The TCP family has failed to achieve consistent high performance in face of the complex production networks: even special TCP variants are often 10x away from optimal performance. We argue this is due to a fundamental architectural deficiency in TCP: hardwiring packet-level event to control responses without understanding the real performance result of its action.
Performance-oriented Congestion Control (PCC) is a new architecture that achieves consistent high performance even under challenging conditions. PCC senders continuously observe the connection between their actions and empirically experienced performance, enabling them to consistently adopt actions that result in high performance.
Read More...
Papers
PCC: Re-architecting Congestion Control for Consistent High Performance
To appear in USENIX NSDI 2015
Mo Dong*, Qingxi Li*, Doron Zarchy**, P. Brighten Godfrey*, Michael Schapira**
*University of Illinois at Urbana Champaign
**Hebrew University of Jeruselem
Slides from talk on cSpeed and PCC
November 6, 2014 at MIT Wireless Seminar
This work is supported by the National Science Foundation and won a 2013 Internet2 Innovative Application Award (under the name BBCC)
Compare PCC and TCP in Action
Use PCC
The PCC architecture requires only sender-side changes to TCP’s rate control algorithm (with no changes to the host-to-host communication protocol), but this prototype is implemented in userspace on top of UDP.
Goto Github Repo
Why TCP's Architecture is Broken
Though using different control algorithms, all TCP's variants share the same hardwired mapping rate control architecture: hardwiring certain predefined packet-level events to certain predefined control responses
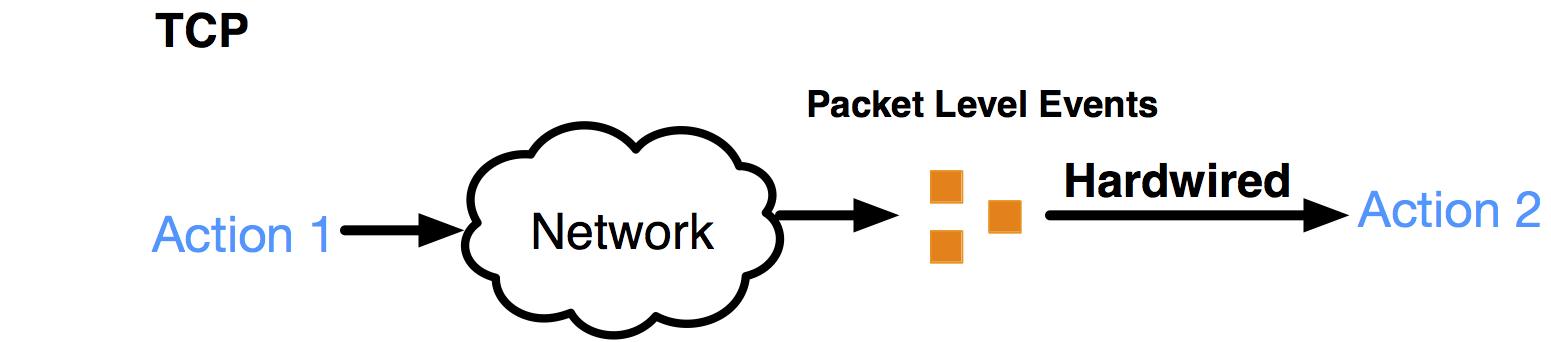 The TCP family's hardwired mapping control architecture
The TCP family's hardwired mapping control architecture
The design rationale behind the hardwired mapping architecture is to make assumptions about the packet-level events. When it sees a packet-level event (e.g. packet loss), TCP assumes the network is in a certain state (e.g. congestion) and tries to optimize performance by triggering a predefined control behavior (e.g. halving window size) as the response to that assumed state. But real networks are complex, with bandwidth varying by 10,000x, virtualization, AQMs, middleboxes and software routers, shallow queues and bufferbloat, congestion loss and random loss. TCP's assumptions fail but it still mechanically carries out the mismatched control response, resulting in severely degraded performance and very unfortunately, without seeing its control action’s actual harm on performance.
How PCC Works
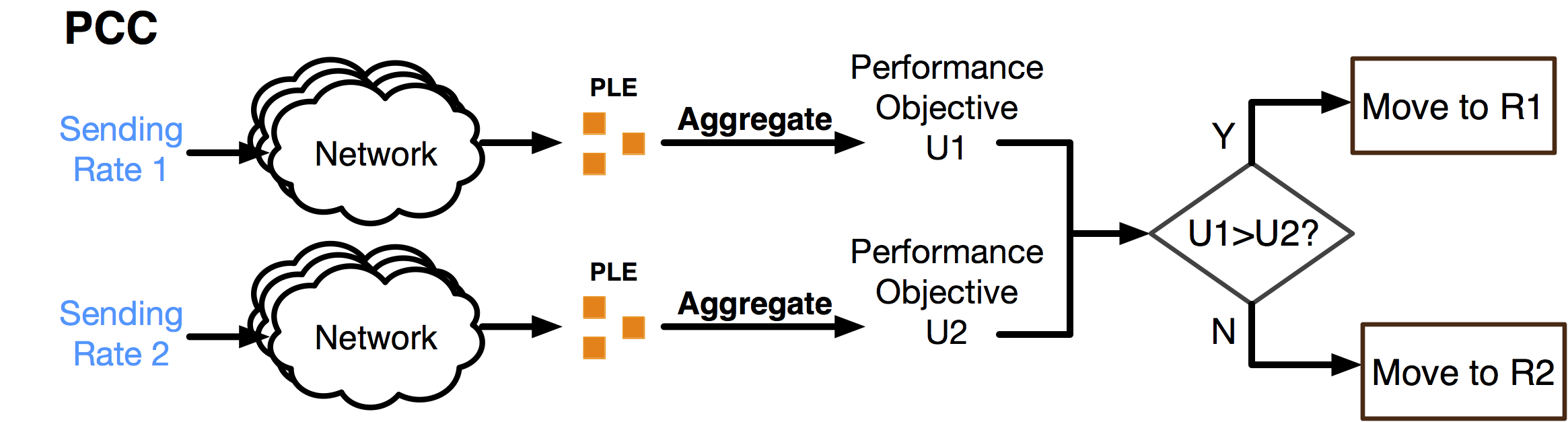 PCC's control architecture is based on emprical observed performancee
PCC's control architecture is based on emprical observed performancee
PCC rises from where TCP fails, by associating a control action (change of sending rate) directly with its effect on real performance. For example, when a sender changes its rate to r and gets SACKs after sending at this rate, instead of trigging any predefined control action, PCC aggregates these packet-level events into meaningful performance metrics (throughput, loss rate, latency, etc.) and combines them into a numerical value u via a utility function describing objectives like “high throughput and low loss rate”. With this capability of understanding the real performance result of a particular sending rate, PCC then directly observes and compares different sending rates’ resulting utility and learns how to adjust its rate to improve empirical utility through a learning control algorithm. By avoiding any assumptions about the underlying potentially-complex network, PCC tracks the empirically optimal sending rate and thus achieves consistent high performance.
High Performance Out of the Box
Big Data Delivery Over the Internet
Based on our large-scale experiments over the global commercial Internet, PCC can beat TCP CUBIC (the Linux kernel default) by more than 10X on 44% of the tested sending-receiving pairs.
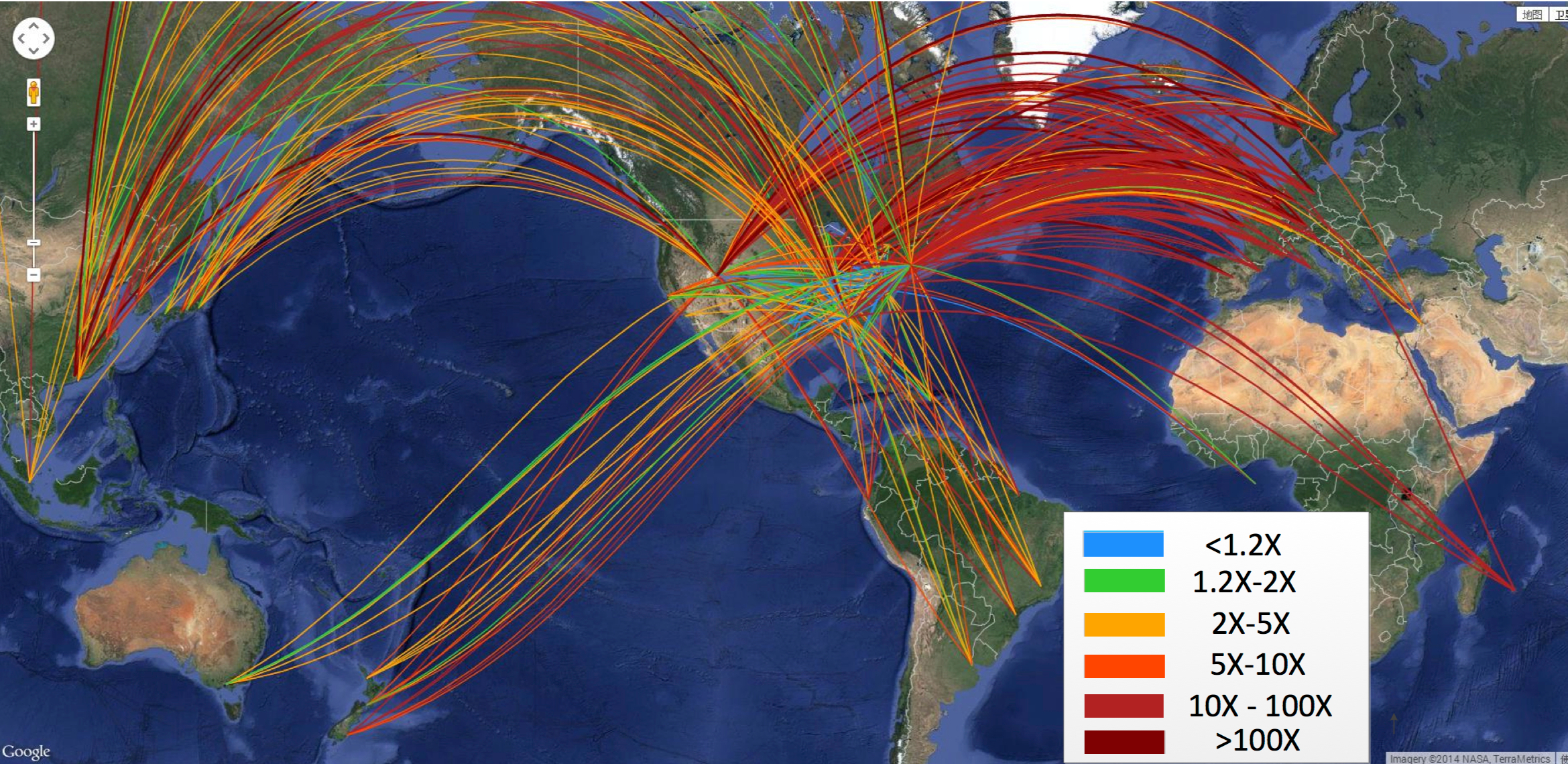 The scale of our global Internet experiments and the improvement of PCC over TCP CUBIC
The scale of our global Internet experiments and the improvement of PCC over TCP CUBIC
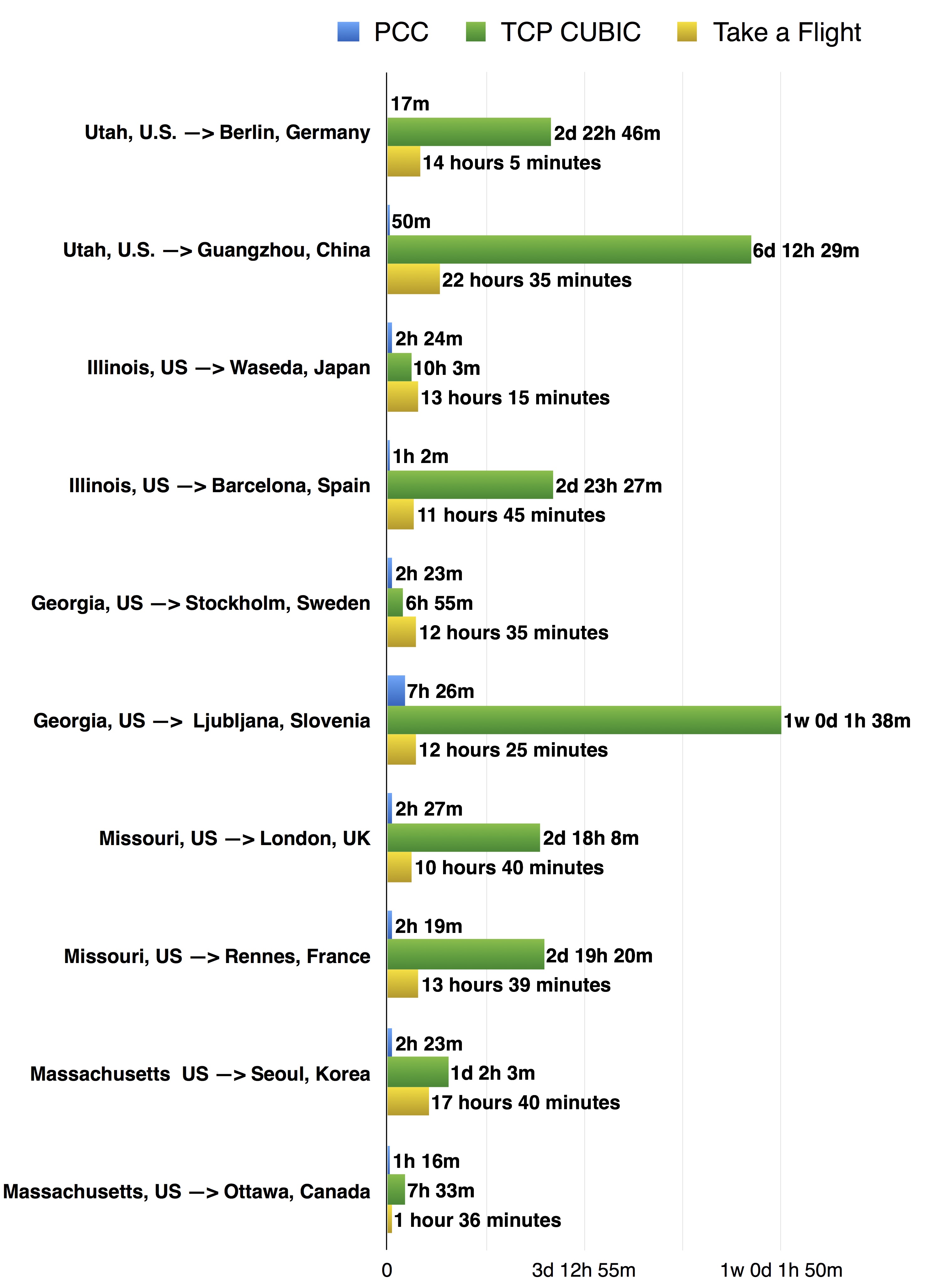
We use several representative samples to compare how long it takes to deliver 100GB of data when using PCC, TCP or just taking a flight and carrying the data with you.
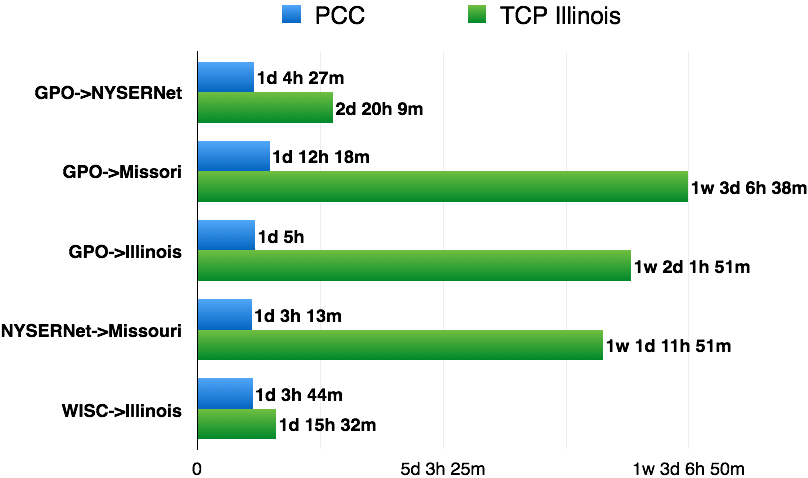
Huge Data Delivery over Dedicated Network
Have huge data (10TB/delivery)? Own a fast network? Can provision dedicated network capacity? Don’t waste your capacity! To test this scenario, we provisioned multiple fully dedicated 800Mbps links across the GENI Internet2 backbone. Here is the time to deliver 10TB data in PCC and TCP Illinois.
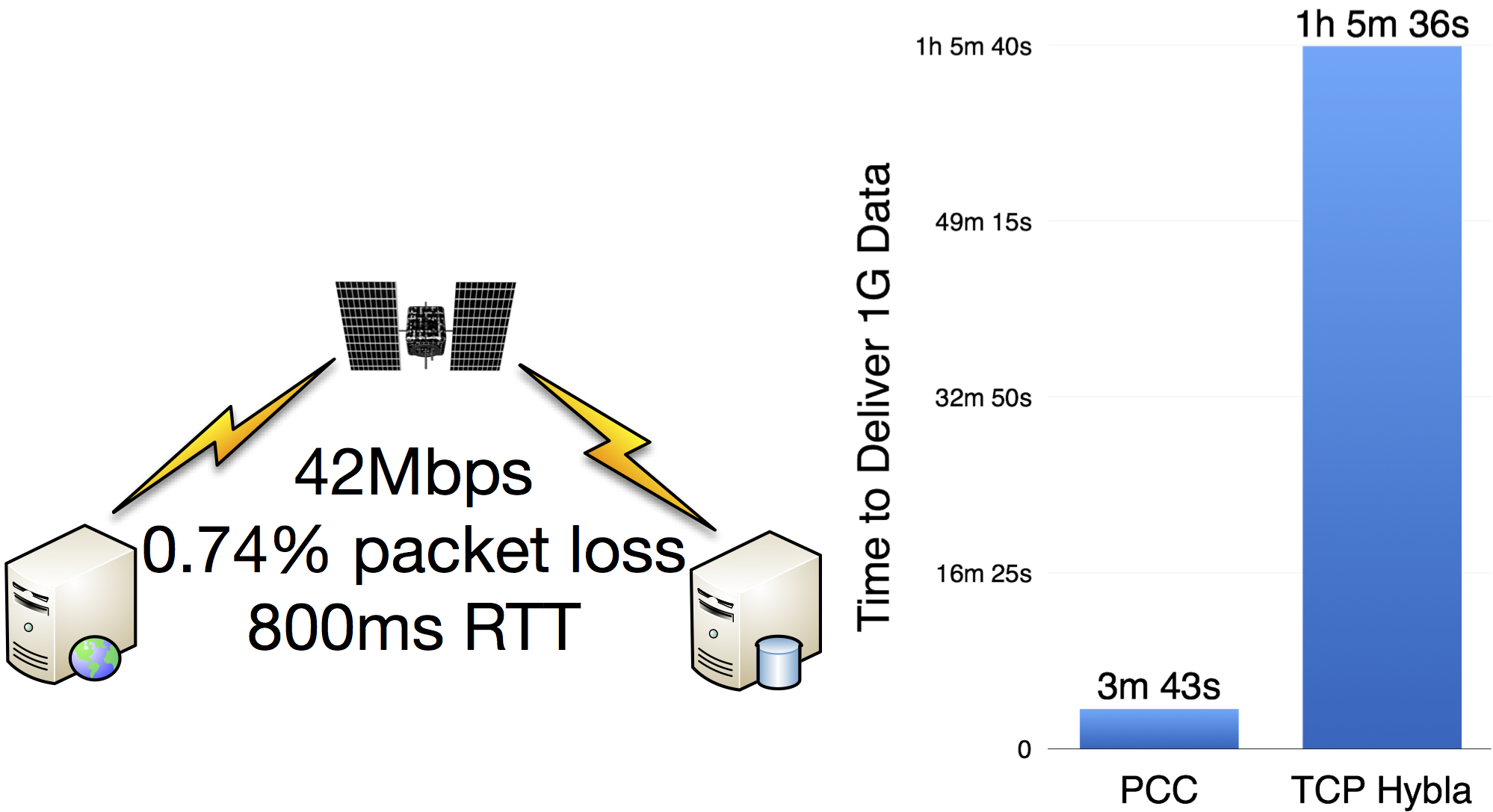
Satellite Internet
On an emulated WINDS satellite Internet connection based on real-world measurement, PCC delivers data 17X faster than TCP Hybla.
Rapidly Changing Networks
We tested TCP and PCC on a network path where available bandwidth, loss rate and RTT are all changing every 5 seconds, with bandwidth ranging from 10Mbps to 100Mbps, latency from 10ms to 100ms and loss rate from 0% to 1%. Compared to TCP variants, PCC tracks the optimal rate closely.
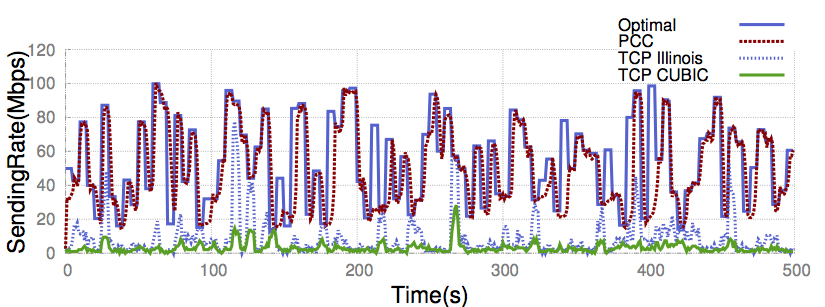 PCC tracks optimal rate closely
PCC tracks optimal rate closely
More in the paper
Our paper details further results showing PCC delivers high performance across a range of challenging conditions. In addition to those above, we test:
- Unreliable lossy links (10-37X vs TCP Illinois)
- Unequal RTT of competing senders (an architectural cure to RTT unfairness)
- Shallow buffered bottleneck links (up to 45X higher performance, or 13X less buffer to reach 90% throughput)
- TCP Incast in data centers, where PCC performs similarly to the purpose-built ICTCP.
Stable Convergence and Fairness
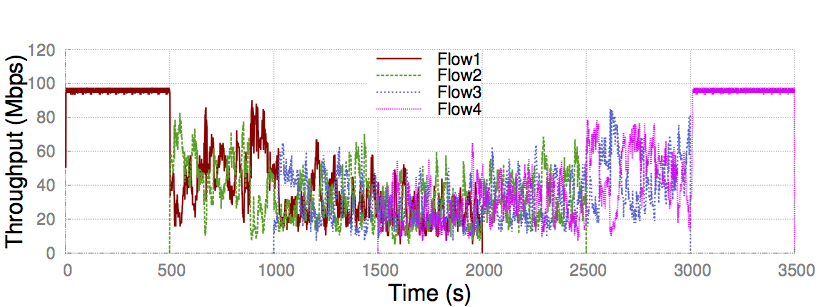
PCC’s control algorithm is selfish in nature. Surprisingly, it can achieve fairness and much more stable convergence than TCP. The following is a typical dumbbell topology convergence experiment, 100Mbps, 30ms latency bottleneck. Four flows sequentially arrive with 500s interval. Each flow sends for 2000s.
PCC converges to fairness point stably.
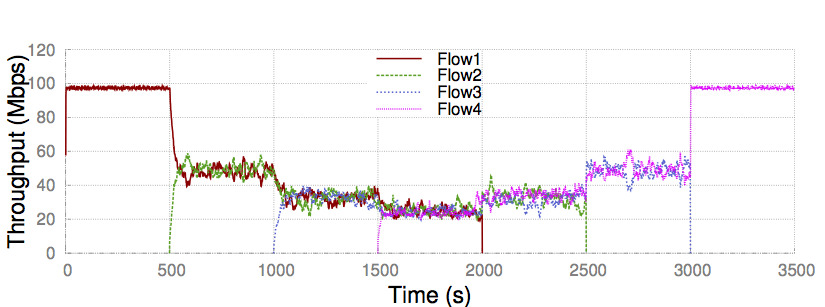
TCP shows very unstable behavior.
Flexible Performance Objectives
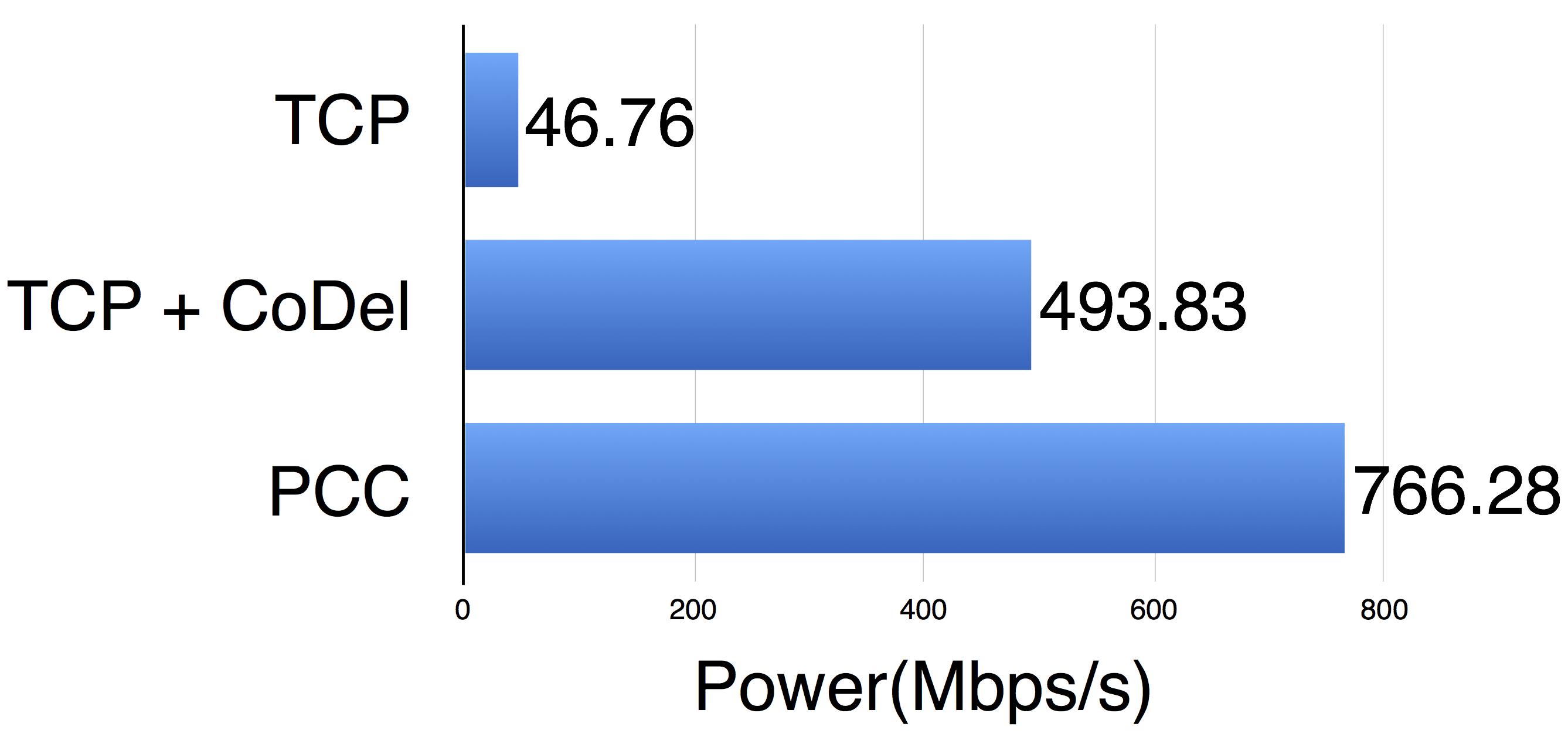
PCC has a feature outside the scope of the TCP family: PCC can directly express different data delivery objectives by simply plugging in different utility functions. Consider an interactive application that wants to get high throughput and low latency, i.e. with the goal of optimizing throughput/latency, defined in previous literature as "power".
When using TCP to deliver data, users of this interactive application will be very upset by the lagging user experience, because TCP does not know the low latency objective, still aggressively fills the network buffer and causes annoying delay known as bufferbloat. To get better latency, either in-network active queue management mechanisms like Codel or a fork lift change of the protocol stack is needed. When using PCC, one can simply plug in the data delivery objective throughput/latency as utility function. Then PCC's control learning algorithm will control the sending rate to empirically optimize this utility function.
As shown in the figure below, PCC caters to interactive application's objective dramatically better than TCP and even achieves more power than TCP with addiontal in-network AQM.
Contact
Mo Dong, Qingxi Li, Doron Zarchy , P. Brighten Godfrey, Michael Schapira